
Un titre volontairement provocateur qui me ferait passer pour un expert en IA. C’est loin d’être le cas ; même si je travaille avec les environnements disponibles en lignes comme ChatGPT (depuis novembre 2022), Gemini ou CoPilot. Les fameuses 10 minutes ont été rendues possibles grâce aux recherches fondamentales des experts en langages neuronaux depuis 15 ans. J’ai peu de mérite.
Si ce que je vais décrire ci-dessous permet à presque tout le monde d’installer une IA en local sur un PC-Mac-Linux, chez soi à la maison ou dans son entreprise, en 10 minutes. Je passe sous silence volontairement le temps que j’ai passé à :
– Comparer les solutions,
– Choisir le système d’exploitation cible,
– Identifier les outils d’IA pré entraînés parmi les modèles prêts à l’emploi via les bibliothèques accessibles en ligne.
En résumé, 6 mois de recherche sur internet, d’échanges avec des experts, pour trouver une solution répondant à divers cas d’utilisation (traitement du langage naturel, génération de texte, classification, etc.).
Des mois de recherche, mais aussi de tests, d’essais, et d’échecs. A plusieurs reprises, l’envie de tout arrêter. Et puis la solution…
Une solution facile
Pour ceux qui veulent des détails sur les caractéristiques techniques permettant la mise en place, je vous renvoie vers ce lien qui spécifie les conditions minimum (caractéristiques techniques). Sinon, pour simplifier, il vous faut une machine assez neuve (même si… voir la configuration que j’ai utilisé), avec une carte graphique, et de l’espace disque.
Considérant que mettre en place un outil d’intelligence artificielle en local nécessite une bonne compréhension de l’infrastructure, des outils de développement, ainsi que des algorithmes d’apprentissage automatique, j’ai choisi la facilité : JAN.
Ce choix s’inscrit dans un processus de simplification de mise en place d’un outil d’intelligence artificielle en local :
– Plus besoin de ré entraîner des modèles à partir de zéro ;
– Economie de temps et de ressources.
Mais il existe des nombreuses autres solutions permettant de rapidement expérimenter et développer des applications basées sur des modèles de génération de texte et de dialogue.
JAN – http://www.jan.ai – se présente comme une équipe de chercheurs et d’ingénieurs en IA orientés open-source, en mode start-up avec la volonté de trouver prochainement un business model équilibré. Pour les seniors, dont je fais partie, ça ressemble à des modèles comme RedHat, croisé avec la démarche de Linus Torvalds (inventeur/promoteur de Linux).
Une IA locale pour quoi faire
Il existe deux réponses possibles pour expliquer les raisons poussant à avoir besoin d’une version locale. Il y a ceux qui veulent voir ce que ça fait. Pourquoi pas. Et les autres.
Les entreprises pourraient faire partie de cette deuxième catégorie. Des entreprises qui souhaitent mettre à disposition de leurs collaborateurs une IA pour répondre à aux besoins métier. Pour les accompagner dans leur activité ; ou Sécuriser les données qui sont analysées.
Dans la mesure où certaines informations doivent rester interne à l’entreprise, disposer d’une IA localement permet ainsi à tous les collaborateurs de bénéficier de la puissance de réponse d’une IA sans s’inquiéter (ou sans inquiéter le chef d’entreprise) de ce que deviennent les informations et comment elles sont récupérées : tout reste en interne.
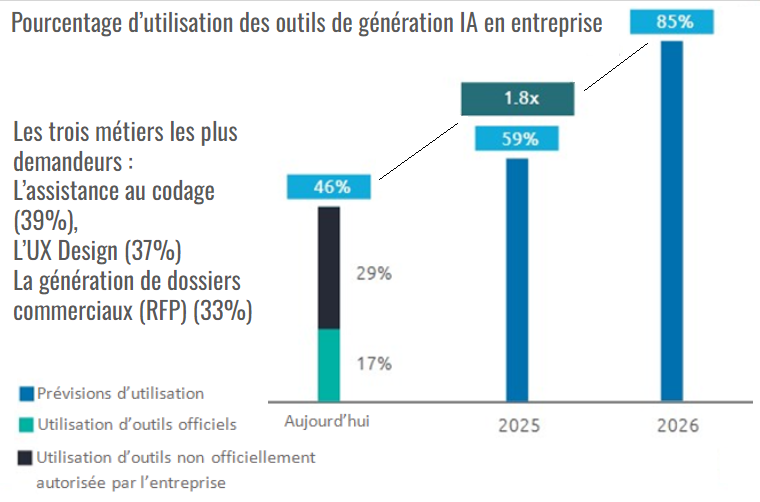
A ce propos, Cap Gemini avait fait en avril 2024 une étude sur les perspectives d’utilisation des outils de génération actuelles et à venir. Il en résulte que nombre de collaborateurs utilisent déjà l’IA sans l’approbation de l’entreprise.
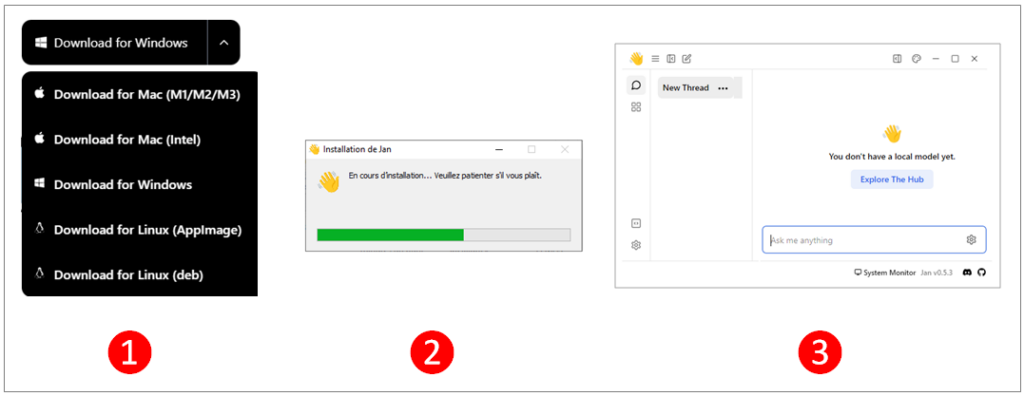
La procédure d’installation : téléchargez l’exécutable et laissez vous guider
Les sources sont disponibles sur jan.ai en diverses versions selon le système d’exploitation cible.
Une fois enregistré en local, vous exécutez l’installeur.
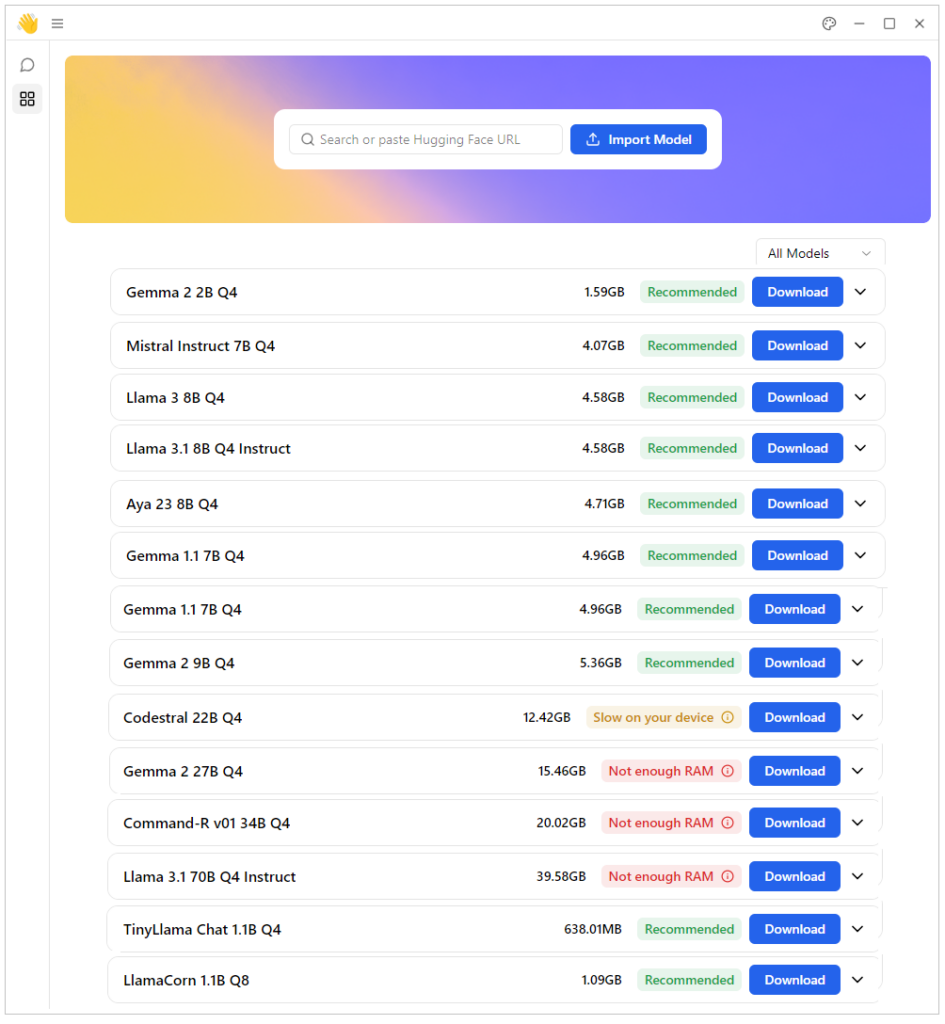
C’est presque tout ce qu’il y a à faire. Reste l’étape du choix du SLM (Small language Model) en cliquant sur « Explore The Hub » et parmi l’ensemble des IA disponibles, l’outil identifie ceux ayant la meilleure performance pour la machine sur lequel vous aurez choisi d’installer l’IA. Les plus téméraires pourront même choisir un modèle qu’ils auraient trouvé ailleurs avec l’option « Import Model ».
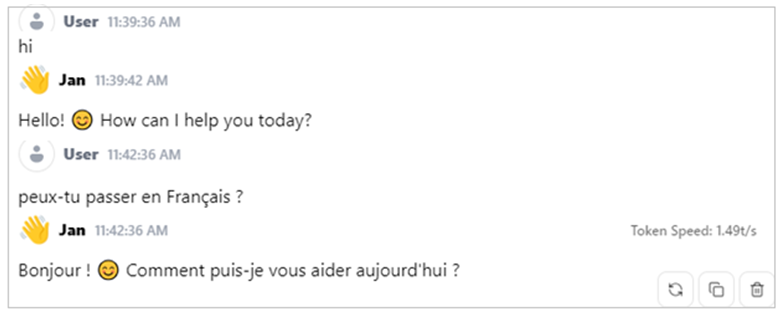
Les 10 minutes ne seront sans doute pas encore écoulées avant que vous puissiez faire votre premier prompt. Pour l’initialisation il vous faudra écrire « Hi ». Une obligation issue du fait que le modèle est à l’origine en Anglais. Puis de lui demander de basculer dans la langue qui vous convient le mieux.
La promesse d’une IA locale vs la réalité
Votre IA est installée, et vous pouvez localement lui poser des questions. Selon le modèle que vous aurez choisi, les réponses seront plus ou moins élaborées. Pour rappel, ChatGPT dispose de plus de 175 Milliards de paramètres ; la version en locale aura sans doute au mieux 9 Milliards de paramètres.
Pour résumé la situation, vous disposez d’un avion de tourisme ; ne lui demandez pas les performances et les qualités techniques d’un avion de chasse.
Concernant, la promesse du tout local, j’ai voulu la mettre à l’épreuve. Et, bien que sceptique quant à l’argument marketing, je me suis trompé. Dès la 2ème question posée, le câble internet était débranché et vérifié que la connexion WiFi était inactive. Et, en effet : ça marche.
Sans rentrer dans les détails techniques, je dois tout de même préciser que lors de ma première installation, je n’avais pas intégrer de carte graphique ; il en avait résulté que les réponses étaient transmise à la vitesse de 1,49 token par seconde. Pour simplifier 1 token équivaut à 1 mot ; J’avais donc des réponses à 90 mots par minute. Pour comparer, les recherches ont montré que la vitesse de lecture moyenne pour les adultes est comprise entre 220 et 350 mots par minute, selon le niveau de concentration et la maîtrise de la langue.
J’ai donc rajouté une carte graphique (voir configuration technique), et suis passé à 32 tokens par seconde (1920 mots par minutes). Résultat largement acceptable.
Pour comparaison, ChatGPT réponds à un rythme d’environ 100 à 200 tokens par seconde, en fonction de la complexité de la réponse et du type d’interaction.
Une IA répondant aux besoins métiers spécifiques : le RAG
Le RAG signifie Retrieval-Augmented Generation (Génération augmentée par la récupération d’informations). Cela permet d’aller chercher des informations spécifiques et à jour qui ne sont pas forcément contenues dans le modèle pré-entraîné de l’IA.
C’est finalement ce que vont chercher les entreprises. Adapter la réponse à des cas métiers spécifiques. Répondre à des questions complexes. Avoir une IA qui colle à leur métier. Les comptables, les avocats, les commerciaux en général seront les populations parmi les plus intéressées pour vouloir en disposer. Le secret des affaires et le besoin de garder les documents confidentiels en interne leurs feront préférer les versions locales aux versions en lignes.
Et ça tombe bien car JAN propose l’option RAG…. Mais…
Les reproches à faire à JAN
Le RAG ne marche pas encore complètement en version Windows. Je teste depuis 1 semaine diverses solutions. Aujourd’hui, JAN est capable d’intégrer de nouveaux documents, mais les « oublie » dès qu’on redémarre l’application. Et en complément, les documents ne peuvent être que du texte. Oubliez l’analyse de graphique, ou de photos.
En parallèle, au-delà des lacunes normales du fait du plus faible nombre de paramètres qui ont permis d’entrainer l’IA qui vous installerez, JAN se remet en Anglais dès qu’il se trouve face à des questions auxquelles il ne sait pas répondre, comme le montre la copie d’écran ci-dessous. C’est un détail ; mais c’est agaçant.
En clair, passé le moment durant lequel il est étonnant de voir à quel point l’IA s’installe et s’utilise facilement, reste le besoin en l’état. Il y en aura peu. Les versions en ligne suffisant largement.
Par contre en version amélioré par RAG, les entreprises devraient s’y pencher. Lancer un projet d’IA locale permettra d’améliorer le travail des équipes. Et les performances globales des entreprises qui auront su innover avant la concurrence.
Caractéristiques techniques minimum pour installer une IA locale
JAN est une plateforme d’IA fonctionne localement sur divers systèmes : Mac équipés de processeurs M1/M2/M3, Windows et Linux. JAN offre la possibilité de faire tourner des modèles IA localement, comme Llama ou Mistral, sans connexion internet, garantissant ainsi la confidentialité des données. Il est également de connecter des API distantes comme celles d’OpenAI.
Application 100% open-source, personnalisable avec des extensions pour adapter les fonctionnalités aux besoins spécifiques de l’utilisateur.
Ci-dessous les paramètres conseillés pour JAN en local. NB : Pour ma part, je l’ai installé sur un PC en windows 10 pro x64, avec un processeur i3 4 cœurs, 8 Go de RAM, 300 Go d’espace disque, et une carte graphique NVidia GeForce RTX 3070. En clair, un processeur et une configuration destinés principalement aux tâches de bureautique et des usages légers en multitâche (sans la carte graphique). Loin de l’IA.
|
Critère |
Détails |
|
Processeurs compatibles |
– Apple Silicon (M1, M2, M3) |
|
– Processeurs Intel et AMD compatibles avec x64 architecture, avec plusieurs cœurs |
|
|
– Optimisation pour GPU NVIDIA pour des modèles lourds (recommandé pour les tâches IA) |
|
|
– Possibilité de connecter à des APIs distantes si le processeur local est moins puissant |
|
|
Systèmes d’exploitation |
– macOS (Apple Silicon et Intel) |
|
– Linux (Debian-based, Ubuntu) |
|
|
– Windows (x64 architecture) |
|
|
RAM |
– Minimum : 8 Go |
|
– Recommandé : 16 Go ou plus pour des modèles plus complexes |
|
|
GPU recommandé (optionnel) |
– NVIDIA pour accélérer l’IA locale (CUDA supporté) |
|
Fonctionnalités clés |
– Fonctionnement local et hors-ligne avec des modèles open-source |
|
– Sécurité accrue avec stockage local de toutes les données |